At the onset of this year, we released an extensive guide on System Design in 2024 to assist individuals in navigating the realm of System Design. This guide meticulously outlines the foundational principles of System Design while also furnishing links to pertinent resources aimed at fostering a comprehensive comprehension of the subject matter. In today’s landscape, developers are increasingly expected to possess a profound understanding of System Design principles and effectively apply them to their roles. Moreover, as one progresses in their career trajectory, System Design inevitably becomes a significant component of interview processes. Hence, acquiring a solid grasp of System Design fundamentals is imperative for paving the path to success both in one’s professional journey and during interviews.
Our objective with this guide is to equip you with the requisite knowledge to excel in your System Design Interview. We aim to elucidate the following aspects:
What is the System Design Interview?
In his blog, Fahim ul Haq, co-founder and CEO of Educative, reflects on the evolution of the coding interview over the past 25 years and offers insights into its future trajectory. Key points include:
During the early 2000s, coding interviews primarily focused on coding tasks and brain teasers. However, the reliance on brain teasers was flawed as it often required knowledge of impractical scenarios unrelated to real-world programming challenges.
The advent of “Web 2.0” and the surge of social media in the mid-2000s ushered in the era of highly scalable large-scale systems. As consumer-facing applications transitioned to the web and cross-platform operations, interviewing practices began to evolve.
Google abandoned brain teasers in favor of real problem-solving with code, marking the beginning of a shift towards System Design in software circles. Despite the existence of distributed systems, best practices were still in the nascent stages, and scaling issues were addressed organically.
The mid-2000s witnessed the introduction of MapReduce, BigTable, and scalable data management, laying the groundwork for establishing practices in large system development. Subsequently, the emergence of cloud technology further shaped the landscape.
Interviewing methodologies continued to evolve, with Facebook integrating “System Design” into their interview process in 2012. Standardized “Toy” problems became prevalent, leading to the contemporary coding interview format.
Today, coding interviews remain dynamic, adapting to evolving product needs and architectural changes. Candidates must possess a solid grasp of software development fundamentals, including System Design, data structures, algorithms, and object-oriented programming principles.
It’s crucial to recognize that interview formats may vary across companies, with Amazon, for instance, incorporating its leadership principles into the interview process. Understanding the specific nuances of the company you’re interviewing with is essential for effective preparation.
In our comprehensive guide to System Design in 2023, we underscore the significance of learning System Design for developers. Mastery of System Design concepts enables developers to confidently address software design challenges throughout their careers and navigate the interview process, particularly as companies increasingly seek individuals capable of working with scalable, distributed systems.
Now equipped with an understanding of the System Design Interview, let’s delve into preparation strategies.
How to prepare for the System Design Interview
In How to prepare for the System Design Interview in 2023, Fahim ul Haq, CEO, and co-founder of Educative, imparts insights gained from conducting numerous System Design Interviews at Microsoft, Facebook, and Educative. Key insights include:
During System Design Interviews, companies aim to assess candidates’ ability to apply knowledge rather than their prior experience with large-scale systems. Candidates with limited experience in this domain can still succeed by adequately preparing for the interview.
System Design Interviews deviate from standard coding interviews as they entail free-form discussions without definitive right or wrong answers. Interviewers seek to evaluate candidates’ capability to lead discussions on system components and evaluate solutions based on given criteria.
Preparation strategies for System Design Interviews should prioritize understanding the fundamentals of distributed systems, architecture of large-scale web applications, and the principles governing the design of distributed systems.
Why it’s important to prepare strategically
As highlighted previously, the approach to preparing for an interview at Amazon may differ significantly from preparing for one at Slack, for instance. Although there are overarching similarities in the interview processes of different companies, there are also unique nuances that necessitate tailored preparation. This underscores the importance of strategic preparation. By methodically crafting an interview prep plan, you instill confidence in yourself for the duration of the process.
Fundamental concepts in the System Design Interview
The complete guide to System Design in 2023 thoroughly addresses the fundamental principles of distributed systems and system design. It is advisable to commence your learning journey with that resource. However, in this guide, we will delve into concepts not extensively covered in the aforementioned guide.
PACELC theorem
While the CAP theorem leaves unanswered the question of “what choices does a distributed system have when there are no network partitions?”, the PACELC theorem provides insights into this inquiry.
According to the PACELC theorem, in a system replicating data:
- If a partition occurs, the distributed system can opt for either availability or consistency.
- Conversely, when the system operates normally without partitions, it can choose between latency and consistency.
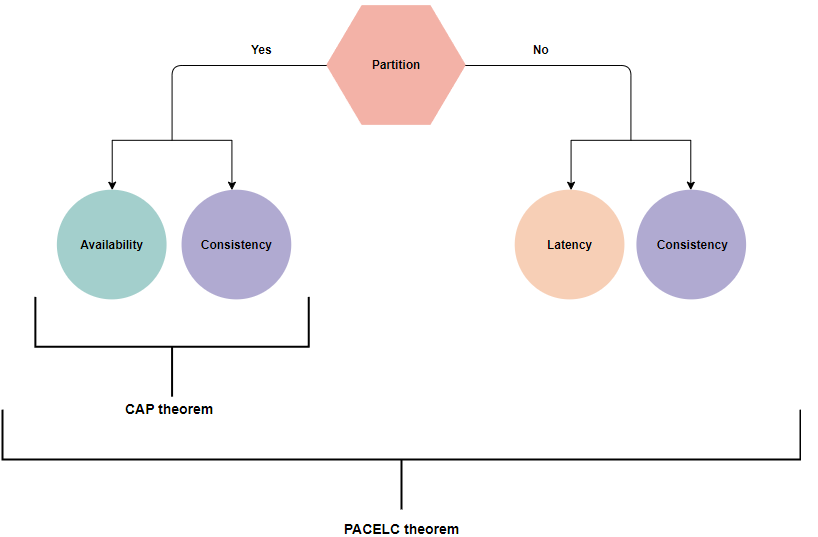
The PACELC theorem shares the first three letters with the CAP theorem, with the ELC serving as its extension. This theorem operates under the assumption of maintaining high availability through replication. In the event of a failure, the CAP theorem takes precedence. However, even without failure, the tradeoff between consistency and latency in a replicated system remains a consideration.
Examples of PC/EC systems include BigTable and HBase, prioritizing consistency at the expense of availability and lower latency consistently. On the other hand, PA/EL systems like Dynamo and Cassandra prioritize availability over consistency during a partition, opting for lower latency otherwise. An instance of a PA/EC system is MongoDB, which prioritizes availability during a partition while ensuring consistency otherwise.
For further insights into these systems, explore Distributed Systems for Practitioners.
Heartbeat
A heartbeat message serves as a vital mechanism for detecting failures within a distributed system. In scenarios where a central server exists, all servers send periodic heartbeat messages to it, affirming their continued operation. Alternatively, in the absence of a central server, servers randomly select a subset of peers and transmit heartbeat messages to them at regular intervals. This proactive approach enables the system to detect potential failures or crashes in the absence of received heartbeat messages over time.
For further insights into heartbeat mechanisms, delve into Grokking the System Design Interview.
AJAX polling
AJAX polling represents a prevalent technique employed by many AJAX applications. The fundamental concept involves the client continuously querying a server for data. Upon making a request, the client awaits the server’s response, which may contain the requested data. In instances where no data is available, the server returns an empty response.
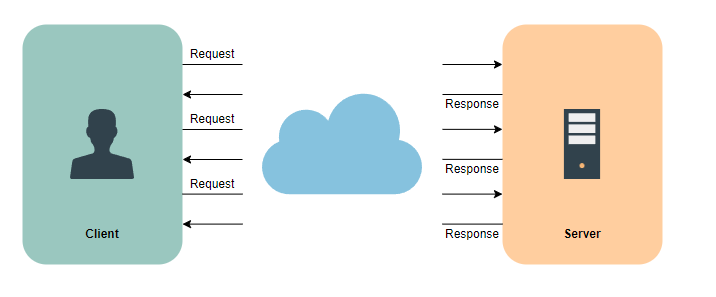
To delve deeper into AJAX polling, explore Scalability & System Design for Developers.
HTTP long-polling
HTTP long-polling involves the client requesting information from the server, but the server may not respond immediately. This technique, also known as “hanging GET,” allows the server to hold the request if no data is currently available for the client. Instead of sending an empty response, the server waits until data becomes available, then sends a complete response to the client. Subsequently, the client promptly re-requests information from the server, ensuring that the server typically has a pending request ready to deliver data in response to an event.
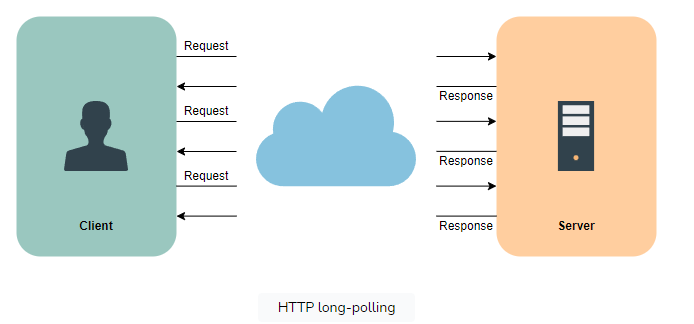
To learn more about HTTP long-polling, check out Scalability & System Design for Developers.
WebSockets
WebSockets facilitate full-duplex communication channels over a single TCP connection, ensuring persistent connectivity between a client and server. This bidirectional connection enables both parties to initiate data transmission at any given moment. Initiated by a WebSocket handshake, upon successful establishment, the server and client can freely exchange data in both directions without constraints.
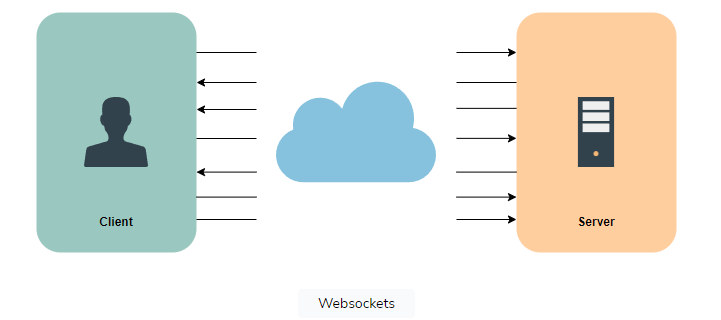
To learn more about WebSockets, check out Scalability & System Design for Developers.
Server-sent events (SSEs)
Through SSEs, a client can establish a prolonged connection with a server, allowing the server to transmit data to the client. However, if the client intends to send data to the server, it would necessitate the utilization of another technology or protocol.
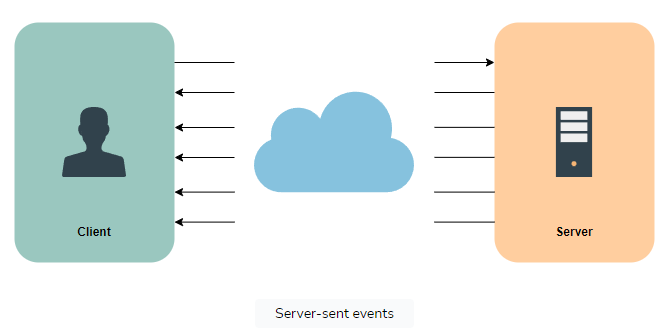
To learn more about server-sent events, check out Scalability & System Design for Developers.
Walkthrough of common System Design Interview questions
During your System Design Interview, you may encounter a variety of different questions. In this walkthrough, we will explore three common questions along with their respective solutions. Additionally, we will offer a resource at the end of this section for further exploration of common SDI questions.
Design Uber
This problem walkthrough has been adapted from another article. For a more comprehensive tutorial, I suggest exploring Design Uber. In that resource, you’ll delve into deeper discussions on use cases, advanced issues, and considerations.
Problem overview
When designing Uber, our system should accommodate two types of users: drivers and users. The system requirements are outlined as follows:
- Drivers can regularly update the service regarding their location and availability.
- Users can view all nearby drivers in real-time.
- Users can request a ride by specifying a destination and pick-up time.
- Nearby drivers are alerted when a user requires a ride.
- Upon ride acceptance, both the driver and user can track each other’s location throughout the trip.
- Upon trip completion, the driver marks the ride as finished and becomes available for other users.
Constraints
Understanding and addressing constraints is pivotal in crafting an effective design for Uber. These constraints, influenced by factors such as time of day and geographical location, shape the architecture of the system. In the context of designing Uber, we must account for specific constraints and estimations, including:
- A projected user base of 300 million and 1 million drivers within the system.
- Anticipated daily activity comprising 1 million active customers and 500 thousand active drivers.
- An estimated volume of 1 million rides per day.
- Requirement for all active drivers to update their current location every three seconds.
- Real-time communication between the system and drivers upon user ride requests.
By comprehensively addressing these constraints, we can develop a robust system architecture capable of meeting the demands of Uber’s operations.
Design considerations
In considering the design for our system, we must address several key factors. Firstly, we need to ensure that our data structures accurately reflect the locations of drivers, updating this information every three seconds. This involves identifying the appropriate grid for each driver based on their previous location and adjusting as necessary.
If a driver’s new position falls outside the current grid, we must remove them from their current grid and insert them into the correct one. Additionally, if a grid reaches its maximum capacity, we must implement a repartitioning process.
Efficient propagation of nearby drivers’ current locations to users is essential. Our system must promptly notify both the driver and user of the car’s location throughout the ride.
Given these requirements, a QuadTree may not be the optimal choice due to potential delays in updates. Instead, we can store the most recent driver positions in a hash table, updating the QuadTree less frequently. Our aim is to ensure that a driver’s current location is reflected in the QuadTree within a 15-second window. We’ll name our hash table DriverLocationHT.
Solving the problem
DriverLocationHT
In setting up the DriverLocationHT hash table, each record must include the DriverID along with the corresponding current and previous locations, requiring a total of 35 bytes per entry. Breaking down the components:
- DriverID (3 bytes)
- Old latitude (8 bytes)
- Old longitude (8 bytes)
- New latitude (8 bytes)
- New longitude (8 bytes)
With an assumed one million entries, the memory requirement will be:
1 million * 35 bytes => 35 MB
Considering bandwidth, obtaining the DriverID and location necessitates (3 + 16 => 19 bytes). With updates gathered every three seconds from 500 thousand daily active drivers, the data received amounts to 9.5 MB every three seconds.
To enhance distribution, DriverLocationHT can be spread across multiple servers based on DriverID, aiding scalability, performance, and fault tolerance. These servers, referred to as “driver location servers,” will also handle two additional tasks: broadcasting driver location updates and storing the information for the duration of the ride.
Broadcasting driver locations
Broadcasting driver locations to users is crucial for the functionality of the system. Utilizing a Push Model, the server can actively push driver positions to relevant users. This can be achieved through a notification service built on the publisher/subscriber model.
When a user opens the app, they initiate a query to the server to identify nearby drivers. Subsequently, on the server-side, the user is subscribed to receive updates from nearby drivers. Each update in a driver’s location within the DriverLocationHT hash table is then broadcasted to all subscribed users, ensuring real-time display of each driver’s current location.
Considering a scenario with one million active users and 500 thousand active drivers per day, let’s assume that each driver has five subscribers. Storing this information in a hash table for efficient updates, we require memory allocation as follows:
(500,000 * 3) + (500,000 * 5 * 8) = 21.5 MB
In terms of bandwidth, with five subscribers per active driver, the total number of subscriptions amounts to:
5 * 500,000 = 2.5 million
Each second, we need to transmit the DriverID (3 bytes) and their location (16 bytes) to these subscribers, resulting in a bandwidth requirement of:
2.5 million * 19 bytes = 47.5 MB/s
Notification service
Efficient implementation of our notification service can be achieved through either HTTP long polling or push notifications. Upon the initial app opening, users are subscribed to nearby drivers. As new drivers enter their vicinity, new user/driver subscriptions are dynamically added. This process involves tracking the areas users are monitoring, which can be complex.
Alternatively, rather than pushing information, the system can be designed for users to pull data from the server. Users provide their current location, allowing the server to identify nearby drivers using the QuadTree. Subsequently, users update their screens to display drivers’ current positions.
For repartitioning purposes, a cushion can be established to allow each grid to expand beyond its limit before partitioning. Assuming grids can grow or shrink by an additional 10%, this approach reduces the burden of grid partitioning.
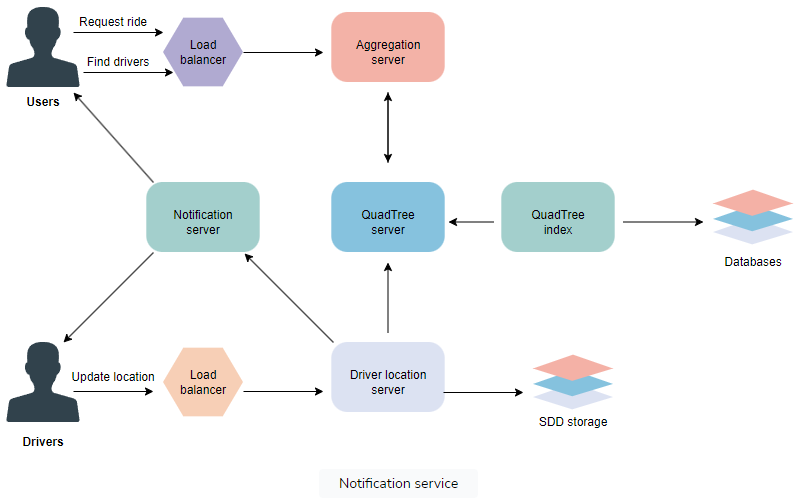
Design TinyURL
This problem walkthrough has been adapted from another article. For a more comprehensive tutorial, I suggest exploring Design TinyURL.
Problem overview
TinyURL is a URL-shortening service that generates shorter aliases for lengthy URLs. These shortened URLs are selected by users and redirect to the original URL. The service proves beneficial as shorter links save space and are more convenient to type. Now, let’s delve into some functional and non-functional requirements essential for the design of TinyURL.
Functional requirements:
- Our service will generate a shorter alias of the original URL that can be easily copied and pasted
- The short link should redirect users to the original link
- Users should have the option to pick a custom short link for their URL
- Short links will expire after a default timespan, which users can specify
Non-functional requirements:
- The system must be highly available
- URL redirection should happen in real-time with minimal latency
- Shortened links should not be predictable
Capacity estimations and constraints
Our system will be read-heavy, with a significant number of redirection requests compared to new URL shortenings. Let’s assume a 100:1 read/write ratio, where redirection requests constitute our reads and new URL shortenings represent our writes.
Traffic estimates
Let’s assume we have 500 million new URL shortenings per month. Based on our 100:1 read/write ratio, we can expect 50 billion redirections during the same period:
100×500 million=50 billion100×500 million=50 billion
We’ll now determine our system’s queries per second (QPS). We’ll take the monthly amount of 50 billion to calculate the new URL shortenings per second:
500 million30 days×24 hours×3,600 seconds=193 URLs/second30 days×24 hours×3,600 seconds500 million=193 URLs/second
Applying the 100:1 read/write ratio again, URL redirections per second will be:
100×193 URLs/second=193,000/second100×193 URLs/second=193,000/second
Storage estimates
Let’s assume we store every URL shortening request and its associated link for five years. Since we expect to have 500 million new URLs every month, the total number of objects we expect to store over five years will be 30 billion:
500 million×12 months×5 years=30 billion500 million×12 months×5 years=30 billion
For now, let’s assume that each stored object will be approximately 500 bytes. This means that we’ll need 15TB of storage for the five year period:
30 billion×500 bytes=15 TB30 billion×500 bytes=15 TB
Bandwidth estimates
We expect 200 new URLs per second for write requests. This makes our service’s total incoming data 100KB per second:
200×500 bytes=100 KB/s200×500 bytes=100 KB/s
For read requests, we expect approximately 20,000 URL redirections every second. Then, total outgoing data for our service would be 10MB per second:
20,000×500 bytes=10 MB/s20,000×500 bytes=10 MB/s
Memory estimates
We’ll need to determine how much memory we’ll need to store the frequently accessed hot URLs’ cache. If we follow the 80/20 rule, then 20% of URLs will generate 80% of traffic. We would like to cache this 20% of hot URLs. Since we have 20,000 requests per second, we’ll get 1.73 billion requests per day:
20,000×3,600 seconds×24 hours=1.73 billion20,000×3,600 seconds×24 hours=1.73 billion
To cache 20% of these requests, we’ll need 173 GB of memory:
0.2×1.7 billion×500 bytes=173 GB0.2×1.7 billion×500 bytes=173 GB
It’s worth noting that there will be a lot of duplicate requests for the same URL. This means our actual memory usage will be less than 173 GB.
System APIs
To ensure smooth interaction with our server, we’ll implement REST APIs to expose its functionality. Below is the API definition for creating and deleting URLs within our service:

Parameters
- api_dev_key (string): This parameter represents the API developer key of a registered account. It’s used to regulate user access based on their allocated quota.
- original_url (string): This parameter specifies the original URL that needs to be shortened.
- custom_alias (string): An optional parameter allowing users to define a custom key for the shortened URL.
- user_name (string): Optional username used in encoding.
- expire_date (string): Optional parameter indicating the expiration date for the shortened URL.
- returns (string): Upon successful insertion, this parameter returns the shortened URL.
Database design
In designing the database for our service, we need to consider the following observations about the data we’re storing:
- The service is expected to store billions of records over time.
- It is predominantly read-heavy, meaning there will be significantly more read operations than write operations.
- Each individual record is relatively small, typically less than 1,000 bytes in size.
- There are no complex relationships between records, except for associating each shortened URL with the user who created it.
Schema
Now, let’s delve into database schemas. Our schema design will involve creating a table to store information regarding URL mappings, along with another table to manage data related to users who have created short links.
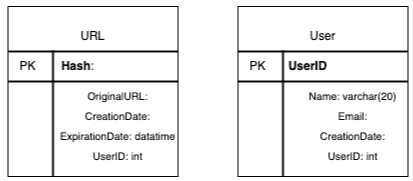
Which database should we use?
For our needs, the optimal choice would be a NoSQL database store such as DynamoDB or Cassandra. Given that we anticipate storing billions of rows with no relationships between the objects, these databases offer the scalability and flexibility required for our system architecture.
Basic System Design and algorithms
In designing our system, a key consideration is how to generate a short and unique key for a given URL. One approach is to encode the URL, computing its unique hash using algorithms like MD5 or SHA256. The resulting hash can then be encoded for display, with options including base36, base62, or base64. For this example, we’ll use base64 encoding.
Next, we must decide on the length of the short key: six, eight, or ten characters. With base64 encoding, a six-character key offers approximately 68.7 billion possible strings, while an eight-character key increases this to around 281 trillion possibilities. Assuming the six-character key is sufficient, we’ll proceed accordingly.
However, using the MD5 algorithm for hashing yields a 128-bit hash value, translating to over 21 characters after base64 encoding. As our system supports only eight characters per short key, we’ll need an alternative approach.
One solution is to truncate the hash value to six (or eight) characters for the key. However, to avoid key duplication, additional steps are necessary. Potential obstacles include the possibility of multiple users entering the same URL, URL encoding variations, and the need for uniqueness.
A workaround involves appending a sequence number to each short link URL, ensuring uniqueness even with identical input URLs from multiple users. This approach resolves potential duplication issues and guarantees each link’s uniqueness.
Data partitioning and replication
In our system, the database will manage information for billions of URLs. To ensure scalability, we must implement partitioning. Let’s explore two partitioning strategies: range-based and hash-based.
Range-based partitioning involves storing URLs in separate partitions based on the first letter of their hash key. For example, all URLs with a hash key starting with “A” would reside in one partition, and so forth. While this method is straightforward, it can lead to imbalanced database servers and uneven load distribution.
Alternatively, hash-based partitioning involves calculating the partition for a stored object based on its hash. Using a hashing function, data is distributed randomly across partitions. However, this approach may result in some partitions becoming overloaded. To address this issue, we can implement consistent hashing, which helps distribute the load more evenly across partitions.
Caching
Our service must have the capability to cache frequently accessed URLs. Implementing a solution such as Memcached allows us to store full URLs along with their respective hashes.
Cache Memory Requirements: Initially, we can allocate approximately 20% of the daily traffic for caching and adjust it based on usage patterns. According to our previous estimations, we anticipate needing 170 GB of memory to cache 20% of the daily traffic effectively.
Cache Eviction Policy: To optimize cache utilization, we will employ the Least Recently Used (LRU) policy. This policy ensures that the least recently accessed URLs are replaced with new entries, prioritizing the caching of more frequently accessed URLs.
Load balancing
To enhance our system’s performance and reliability, we can implement a load balancing layer in three key areas:
- Between clients and application servers
- Between application servers and database servers
- Between application servers and cache servers
We can begin by adopting the Round Robin approach, which evenly distributes incoming requests among the available servers. This ensures optimal utilization of resources and prevents any single server from becoming overwhelmed with requests.
Design Instagram
This problem walkthrough is adapted from another article. For a more detailed tutorial, I recommend checking out the Design Instagram resource.
Problem overview
Instagram is a social media platform that enables users to share photos and videos with others. Users can share content publicly or privately. In this design, we aim to create a simplified version of Instagram where users can share photos, follow each other, and view a personalized news feed. The news feed will display top photos from users whom the viewer follows.
System requirements and goals
Let’s explore both functional and non-functional requirements for the system.
Functional requirements:
- Here are the functional requirements for the system:
- Users should have the capability to search based on photo or video titles.
- Users should be able to upload, download, and view photos and videos.
- Users should have the ability to follow other users.
- The system should generate a news feed containing the top photos and videos from the users that the user follows.
Non-functional requirements:
- Here are the non-functional requirements for the system:
- The service should maintain a high level of availability.
- The acceptable latency for accessing the news feed should be around 200 milliseconds.
- The system should be reliable to ensure that photos and videos are never lost.
Capacity estimations and constraints
We will base our approach off these numbers:
- 500 million total users
- 1 million daily active users
- 2 million new photos every day (at a rate of 23 new photos/second)
- Average photo file size of 200 KB
- Total space required for 1 day of photos: 2 million * 200 KB => 400 GB
- Total space required for 10 years: 400 GB * 365 days * 10 years => 1,460 TB
High-level system design
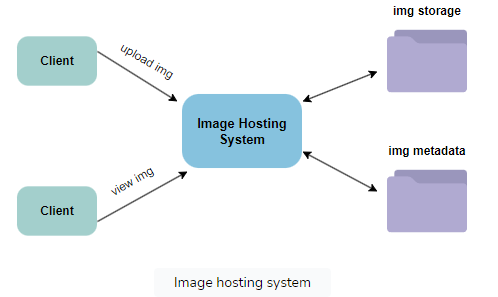
The system needs to facilitate user interactions for uploading and viewing media content. This entails having servers dedicated to storing media files, as well as a separate database server to store metadata associated with the media.
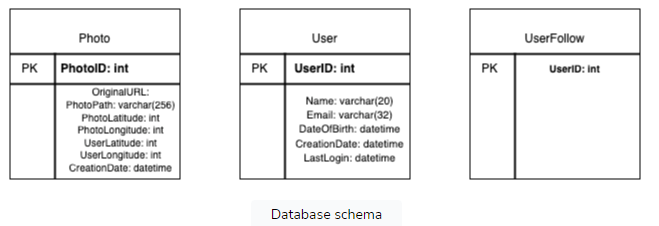
Database schema
Storing the outlined schema in a relational database management system (RDBMS) is a conventional approach. However, scalability challenges often emerge with relational databases.
Alternatively, we can opt for a NoSQL database to manage key-value pairs for the schema. Metadata for photos and videos can be structured within a table, with the PhotoID serving as the key and an object containing attributes like PhotoLocation, UserLocation, CreationTimestamp, and more as the value.
For managing relationships between users and photos, as well as a user’s followed accounts, a wide-column datastore like Cassandra can be employed. In the UserPhoto table, UserID can act as the key, with PhotoIDs owned by the user stored in a separate column. This pattern mirrors the structure of the UserFollow table.
To store the actual media files, a distributed file storage system such as HDFS can be utilized.
Data size estimation
We’ll estimate the data volume for each table and the total storage requirement over a span of 10 years.
User
Every entry in this table will occupy 68 bytes, considering each int and dateTime as 4 bytes:
UserID(4 bytes) + Name(20 bytes) + Email(32 bytes) + DateOfBirth(4 bytes) + CreationDate(4 bytes) + LastLogin(4 bytes) = 68 bytes
For 500 million users, the total storage required would be 34 GB:
500 million * 68 = 34 GB
Photo
Each entry in this table will consume 284 bytes:
PhotoID(4 bytes) + UserID(4 bytes) + PhotoPath(256 bytes) + PhotoLatitude(4 bytes) + PhotoLongitude(4 bytes) + UserLatitude(4 bytes) + UserLongitude(4 bytes) + CreationDate(4 bytes) = 284 bytes
If 2 million new photos are uploaded daily, the storage requirement for one day would be 0.568 GB:
2 million * 284 bytes = 0.568 GB/day
Over 10 years, the storage needed would be 2 TB.
UserFollow
Each record in this table will occupy 8 bytes. With 500 million users following an average of 500 other users each, the UserFollow table will require 2 TB of storage:
500 million users * 500 followers * 8 bytes = 2 TB
The cumulative storage space needed for all tables over 10 years will be approximately 4 TB:
32 GB + 2TB + 2TB = Approx: 4TB
Component design
Photo uploads typically take longer than reads due to disk operations. The slow upload process can exhaust all available connections, hindering reads from being served during high write loads. To address this bottleneck, we propose segregating reads and writes onto distinct servers. This segregation prevents system overload, enabling efficient optimization of each operation.
Reliability and redundancy
Implementing redundancy within the system provides a backup solution in case of system failures, ensuring zero data loss and maintaining high application reliability. By storing multiple replicas of each photo and video, the system can seamlessly retrieve media from alternative servers in case of server failures. This redundancy strategy extends to other components of the architecture, ensuring uninterrupted system operation even in the event of service failures.
Data sharding
A potential approach for a metadata sharding service involves partitioning based on PhotoID. To address the outlined challenges, we can create distinct PhotoIDs and determine a shard number using the formula PhotoID % 10. In this scenario, there’s no need to concatenate ShardID with PhotoID since PhotoID will be globally unique within the system.
Generating PhotoIDs
Utilizing an auto-incrementing sequence in each shard to define PhotoID isn’t feasible. Without knowing the PhotoID, determining the shard where it will be stored becomes challenging. One potential solution involves allocating a distinct database instance dedicated to generating auto-incrementing IDs.
Assuming our PhotoID can be accommodated within 64 bits, we can establish a table comprising solely a 64-bit ID field. Whenever a new photo is added to our system, a new row can be inserted into this table, and the ID retrieved can serve as the PhotoID for the new photo.
Ensuring reliability
The key-generating database may represent a single point of failure within the system. To address this concern, a potential solution involves establishing two databases for key generation. One database could be responsible for generating even-numbered IDs, while the other handles odd-numbered IDs. In MySQL, the following script could be utilized to define such sequences:

To ensure reliability, we can implement a load balancer to manage both of these databases. Utilizing Round Robin between them can effectively handle downtime scenarios. It’s possible that one server may generate more keys than the other; however, such discrepancies won’t adversely impact our system. Additionally, we can further enhance this design by creating separate ID tables for various objects within our system, such as Users, Photo-Comments, and others.
Load balancing
To effectively manage the delivery of photos on a large scale and serve users worldwide, our service would require a robust photo delivery system. One approach to achieve this is by deploying cache servers that are strategically distributed across various geographic locations. This allows us to push content closer to users, thereby enhancing the speed and efficiency of content delivery.
List of common System Design Interview questions
- Design a global chat service like Facebook Messenger or WhatsApp
- Design a social network and message board service like Quora or Reddit
- Design a global file storage and sharing service like Dropbox or Google Drive
- Design a global video streaming service like YouTube or Netflix
- Design an API rate limiter for sites like Firebase or GitHub
- Design a proximity server like Yelp or Nearby Places/Friends
- Design a search engine related service like Type-Ahead
- Design Ticketmaster
- Design Twitter
- Design a Web Crawler
For comprehensive guidance on tackling System Design Interview problems and mastering all the fundamental concepts, I highly recommend referring to “Scalability & System Design for Developers.” This resource offers invaluable insights and strategies to excel in System Design interviews.
How to approach any SDI question
In the “Top 10 System Design Interview Questions for Software Engineers,” we provide a systematic approach to tackling any System Design Interview (SDI) question. Let’s delve into the key steps of this approach:
- State What You Know/Clarify the Goals: Begin by articulating your understanding of the problem and its goals. Outline the required features, anticipated challenges, and expected traffic volume. This demonstrates your analytical skills and allows for any clarifications or corrections from the interviewer before proceeding with the solution.
- Describe Trade-Offs: Throughout your solution, discuss the trade-offs associated with each design decision. Highlight both the advantages and drawbacks to showcase your ability to weigh different options and make informed choices.
- Discuss Emerging Technologies: Conclude your solution by exploring how emerging technologies, such as machine learning, could enhance or optimize the system in the future. This demonstrates your forward-thinking approach and readiness to adapt to evolving industry trends.
By following this structured approach, you’ll not only address the immediate requirements of the SDI question but also showcase your strategic thinking and potential for future-oriented solutions.
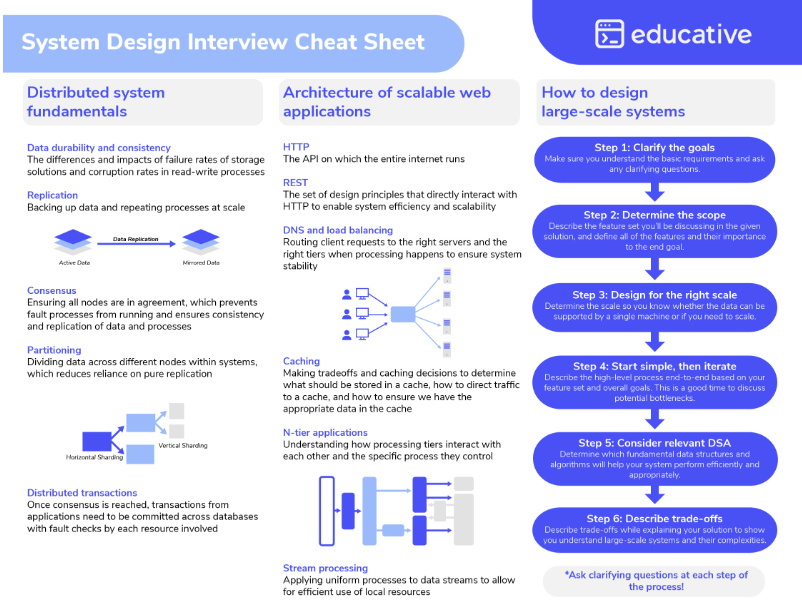
System Design Interview cheat sheet
Here’s a quick reference cheat sheet for System Design Interviews: